- Паттерны для систем отчетности (ETL): как создавать эффективные решения для обработки данных
- Что такое ETL и почему это важно?
- Основные паттерны для систем ETL
- Паттерн "Последовательная обработка" (Sequential Processing)
- Паттерн "Параллельная обработка" (Parallel Processing)
- Паттерн "Дельта-обновление" (Incremental Loading)
- Паттерн "Обработка ошибок и повторные попытки" (Error Handling & Retry)
- Паттерн "Обработка в реальном времени" (Real-Time Processing)
- Паттерн "Многодоступные источники" (Multi-Source Integration)
- Практические советы по реализации паттернов ETL
Паттерны для систем отчетности (ETL): как создавать эффективные решения для обработки данных
В современном мире объем данных растет с каждым днем, и организации сталкиваются с необходимостью непрерывно отслеживать, анализировать и использовать эти данные для принятия управленческих решений. Именно поэтому системы отчетности, основанные на процессах ETL (Extract, Transform, Load), становятся неотъемлемой частью архитектуры данных любой компании. В этой статье мы подробно разберем основные паттерны для систем ETL, расскажем о лучших практиках их реализации и поделимся нашим опытом в создании эффективных решений.
Что такое ETL и почему это важно?
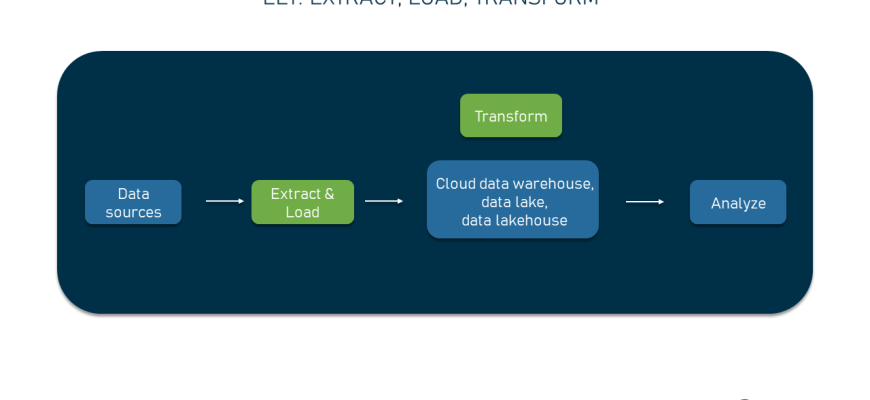
Перед тем как погрузиться в детали паттернов, важно понять базовые принципы ETL. Это процесс извлечения данных из различных источников, их преобразования (очистки, агрегирования, форматирования) и загрузки в хранилище данных, предназначенное для аналитики и отчетности. Этот подход позволяет объединить разнородные данные в единое информационное пространство, что значительно ускоряет аналитические процессы и снижает вероятность ошибок.
Ключевая ценность ETL:
- Автоматизация: минимизация ручных вмешательств и снижение риска ошибок.
- Интеграция данных: объединение информации из разнородных источников.
- Обеспечение актуальности: своевременное обновление данных для аналитики в режиме реального времени или по расписанию.
Эффективно построенная архитектура ETL повышает качество бизнес-решений и позволяет быстрее реагировать на изменения рынка и внутренние потребности компании.
Основные паттерны для систем ETL
Существует множество подходов и паттернов к построению систем ETL. Каждый из них подходит для определенных условий и бизнес-запросов. Ниже мы расскажем о самых популярных и эффективных паттернах, приводя реальные примеры их применения.
Паттерн "Последовательная обработка" (Sequential Processing)
Этот паттерн подразумевает последовательное выполнение этапов ETL: сначала извлечение, затем преобразование и, наконец, загрузка данных. Он прост в реализации и подходит для небольших и средних систем, когда объем данных не превышает определенного порога и требования к скорости не очень высокие. В таком режиме легко отследить ошибку и отладить каждый этап отдельно.
Пример:
- Извлечение данных из базы данных CRM.
- Очистка и форматирование данных для аналитического отчета по продажам.
- Загрузка подготовленных данных в дата-warehouse.
Паттерн "Параллельная обработка" (Parallel Processing)
Когда объем данных существенно увеличивается, необходимо разделять процессы для повышения скорости обработки. Параллельная обработка позволяет запускать несколько потоков или процессов одновременно, обрабатывая разные части данных. Для этого часто используют технологии потоковой обработки и распределенные системы, такие как Apache Spark или Apache Flink.
Плюсы:
- Высокая производительность и снижение времени обработки.
- Масштабируемость при росте объемов данных.
Минусы:
- Сложность в реализации и управлении.
- Требования к инфраструктуре.
Паттерн "Дельта-обновление" (Incremental Loading)
Дельта-обновление, это подход, при котором обрабатываются только новые или измененные данные, а не весь объем каждое выполнение ETL. Такой паттерн позволяет значительно сократить объем работы и снизить нагрузку на системы.
Основные способы реализации:
- Использование временных меток последнего обновления.
- Отслеживание изменений через логирование транзакций.
Пример:
- Обновление данных в таблице продаж только за последний день.
- Загрузка в хранилище только новых клиентов.
Паттерн "Обработка ошибок и повторные попытки" (Error Handling & Retry)
Ни одна система не обходится без ошибок. Поэтому важно проектировать ETL так, чтобы он мог реагировать на сбои, логировать их и автоматически повторять попытки. Этот паттерн повышает надежность всей системы и позволяет избегать потери данных.
Реализация включает:
- Логирование ошибок.
- Механизмы автоматического повторного запуска.
- Информирование менеджеров о критичных ошибках.
Паттерн "Обработка в реальном времени" (Real-Time Processing)
Когда аналитика должна быть максимально актуальной, используют паттерн потоковой обработки данных в реальном времени. Для этого применяют такие системы, как Apache Kafka, Apache Pulsar, или встроенные возможности облачных платформ.
Плюсы:
- Обновление данных практически мгновенно.
- Позволяет оперативно реагировать на события.
Минусы:
- Сложность внедрения и обслуживания.
- Высокие требования к инфраструктуре.
Паттерн "Многодоступные источники" (Multi-Source Integration)
Часто данные приходят из нескольких источников: базы данных, файлы, REST API, внешние системы. В этом случае используется паттерн интеграции данных из различных источников с учетом особенностей каждого из них.
| Источник | Особенности | Реализация |
|---|---|---|
| Базы данных | Форматы SQL, транзакции | Использование ETL-инструментов, JDBC/ODBC |
| Файлы | CSV, Excel, XML | Парсеры, скрипты для интеграции |
| API | REST, SOAP | HTTP-запросы, парсеры JSON/XML |
Практические советы по реализации паттернов ETL
Чтобы системы ETL работали максимально эффективно, необходимо придерживаться нескольких важных правил:
- Автоматизация процессов: применение оркестрационных инструментов типа Apache Airflow, Prefect или Luigi.
- Модульность и повторное использование: создание универсальных компонентов для извлечения, преобразования и загрузки.
- Мониторинг и логирование: постоянное отслеживание состояния процессов и своевременное реагирование на ошибки.
- Обеспечение безопасности данных: шифрование, аутентификация и разграничение доступа.
- Масштабируемость: проектировать архитектуру так, чтобы она могла расти вместе с объемами данных и бизнес-потребностями.
Вопрос: Какие паттерны лучше всего подходят для систем в условиях быстрого роста данных и необходимости обработки данных в реальном времени?
Ответ: Для условий быстрого роста данных и необходимости обработки в реальном времени лучше всего подходят паттерны "Параллельная обработка" и "Обработка в реальном времени". Параллельная обработка позволяет ускорить работу с большими потоками данных, распределяя задачи между несколькими узлами или потоками. Для получения данных в реальном времени — использование паттерна потоковой обработки с системами типа Kafka, Apache Flink или Spark Streaming. Совмещение этих подходов обеспечивает масштабируемость и своевременную актуальность аналитики, что особенно важно в условиях динамичного бизнеса.
Построение систем отчетности на базе паттернов ETL, это тонкая наука и искусство одновременно. От выбора правильных подходов зависит не только скорость и надежность обработки данных, но и качество бизнес-решений, которые принимаются на их основе. Важно учитывать особенности ваших данных, объемы, требования к скорости обновлений и инфраструктуру. Ориентируясь на лучшие практики и не бойтесь экспериментировать — именно так создаются действительно эффективные и устойчивые системы.
Напоминаем, что правильная архитектура ETL — это залог успешною работы любой аналитической системы, которая должна служить бизнесу долгие годы и помогать достигать новых высот.
Подробнее
| Паттерн обработки данных | Построение системы мониторинга | Инструменты автоматизации ETL | Обработка ошибок в ETL | Реализация потоковой обработки данных |
| Sequential Processing | Monitoring Tools | Apache Airflow | Error Handling in ETL | Streaming Platforms |
| Parallel Processing | Alerting Systems | Luigi, Prefect | Retry Mechanisms | Apache Kafka |
| Incremental Loading | Logging and Alerts | ETL-инструменты | Error Logging | Apache Flink |
| Real-Time Processing | Performance Optimization | Spark Streaming | Error Recovery | Apache Pulsar |