- Паттерны для систем мониторинга: как создавать эффективные решения для наблюдения за инфраструктурой
- Что такое паттерны в системах мониторинга?
- Основные преимущества использования паттернов
- Классические паттерны мониторинга: основные типы и примеры
- Паттерн "Здоровье системы"
- Паттерн "Анализ логов"
- Паттерн "Сложные сценарии событий"
- Концепции проектирования паттернов для систем мониторинга
- А. Модульность и масштабируемость
- Б. Автоматизация и сценарии реагирования
- В. Интеграция и стандартизация
- Практическое внедрение паттернов: шаги и советы
Паттерны для систем мониторинга: как создавать эффективные решения для наблюдения за инфраструктурой
В современном мире IT-индустрии системы мониторинга занимают ключевое место в обеспечении стабильной работы инфраструктуры, приложений и сервисов. Без правильно настроенных паттернов и подходов, поддержание высокой надежности и своевременного реагирования становится затруднительным. В этой статье мы поделимся нашим опытом и расскажем, как разрабатывать и внедрять паттерны систем мониторинга, которые действительно работают.
В чем заключается основная задача паттернов систем мониторинга?
Обеспечить стабильное и своевременное обнаружение проблем, их классификацию и автоматическое реагирование, что минимизирует время простоя и повышает общую эффективность IT-инфраструктуры.
Что такое паттерны в системах мониторинга?
Под паттернами в системах мониторинга мы понимаем стандартные или типовые решения, шаблоны, схему организации процессов и инструментов для обеспечения контроля за различными аспектами инфраструктуры и приложений. Такой подход позволяет систематизировать работу, повысить эффективность и облегчить масштабирование системы наблюдения.
Использование паттернов помогает ответить на ключевые вопросы: какие метрики отслеживать, как реагировать на сбои, как автоматизировать процессы обнаружения и устранения проблем, и как обеспечить высокую доступность систем мониторинга.
Основные преимущества использования паттернов
- Стандартизация: одни и те же решения применяются во всех проектах и командах.
- Масштабируемость: легко расширять и добавлять новые компоненты.
- Автоматизация: позволяют строить автоматические реакции и оповещения.
- Повышение надежности: систематические методы помогают уменьшить число пропущенных инцидентов.
- Облегчение поддержки: простое внедрение и обучение новых сотрудников.
Классические паттерны мониторинга: основные типы и примеры
Для построения эффективной системы наблюдения за инфраструктурой важно знать, какие шаблоны чаще всего применяются. Рассмотрим самые распространенные паттерны, их особенности и практическое применение.
Паттерн "Здоровье системы"
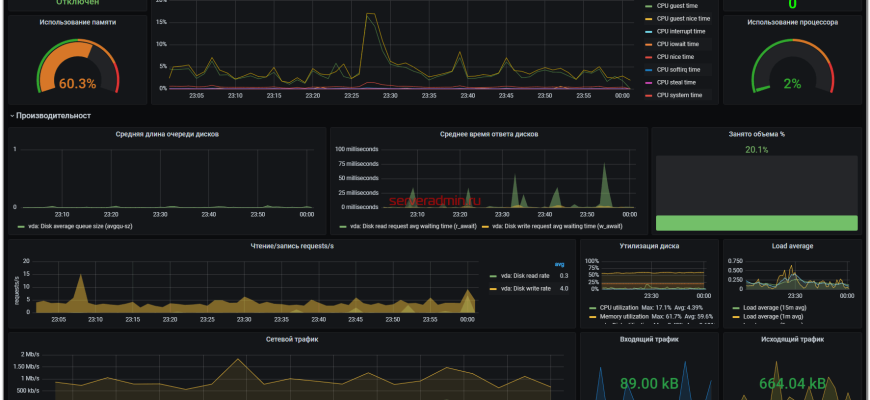
Этот паттерн предполагает мониторинг базовых метрик состояния системы, таких как загрузка CPU, использование памяти, дисковое пространство, состояние сети. Обычно реализуется через агрегированные дашборды, которые агрегируют показатели из разных источников и показывают общее состояние системы.
| Метрика | Стандартное пороговое значение | Рекомендуемый инструмент | Действие при превышении порога | Пример |
|---|---|---|---|---|
| Загрузка CPU (%) | 80 | Prometheus, Grafana | Отправить оповещение, запуск автоматического масштабирования | Загрузка CPU > 90% в течение 5 минут |
| Использование памяти (%) | 75 | Zabbix | Рассмотреть увеличение ресурсов или оптимизацию приложений | Память превышает 80% |
| Свободное дисковое пространство | 20 GB | Nagios, Zabbix | Очистка диска или добавление хранилища | На диске осталось менее 10 GB |
Паттерн "Анализ логов"
Этот паттерн включает автоматический сбор, обработку и анализ логов для обнаружения нестандартных ситуаций или ошибок. Тут активно используются инструменты типа Elastic Stack (ELK), Graylog, и Splunk. Его важной задачей является автоматизация поиска инцидентов по логам.
- Обработка логов в реальном времени
- Настройка правил поиска аномалий
- Автоматическая классификация инцидентов
Паттерн "Сложные сценарии событий"
Этот паттерн предусматривает построение сценариев реакции на цепочку событий. Например, если обнаружена ошибка на сервере, связанная с сетью, и при этом нагрузка резко возросла, система должна автоматически отправить уведомление и инициировать соответствующие процедуры.
Такой подход является основой для реализации систем автоматического устранения инцидентов (Auto-healing) и предотвращения расширения проблем;
Концепции проектирования паттернов для систем мониторинга
Создание эффективных паттернов требует глубокого понимания архитектуры и бизнес-процессов, а также применения нескольких ключевых концепций.
А. Модульность и масштабируемость
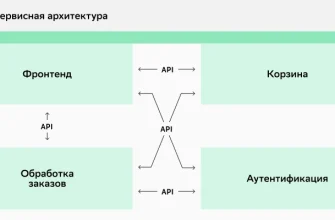
Важно проектировать систему так, чтобы новые компоненты могли добавляться без существенных изменений в существующих. Использование микросервисной архитектуры и API способствует этому.
Б. Автоматизация и сценарии реагирования
Основная идея — автоматическое восстановление работоспособности без человеческого вмешательства, если это возможно, либо предварительная подготовка для быстрого реагирования оператора.
В. Интеграция и стандартизация
Взаимодействие различных инструментов и платформ, унификация форматов данных облегчают обработку информации и повышают эффективность системы.
Практическое внедрение паттернов: шаги и советы
- Анализ инфраструктуры и требований: определите ключевые метрики, логические цепочки, возможные сценарии ошибок.
- Выбор инструментов: исходя из целей — Prometheus, Grafana, ELK, Zabbix и другие.
- Разработка и тестирование паттернов: настройка базовых сценариев и автоматических процедур.
- Мониторинг и корректировка: постоянное отслеживание работы системы и её улучшение.
- Обучение команды: вливайте лучшие практики в команду, регулярно обновляйте знания.
Создание и внедрение паттернов для систем мониторинга, это постоянный процесс, требующий глубокого понимания инфраструктуры и бизнес-процессов. Эффективные шаблоны помогают не только обнаружить проблему в самом начале, но и снизить время отклика, а также повысить надежность всей системы в целом. Используйте проверенные решения, адаптируйте их под свои нужды и не бойтесь экспериментировать, это залог успеха!
Подробнее
| мониторинг серверов | автоматизация реагирования | системы логирования | метрики производительности | автоматизация инцидентов |
| настройка alerting | оптимизация систем мониторинга | интеграция инструментов | метрики сети | управление ошибками |
| инфраструктурный мониторинг | обработка логов | инструменты автоматизации | критические метрики | широкая автоматизация |
| мониторинг оборудования | выявление аномалий | единые стандарты | автоматические отчеты | приоритеты реагирования |
| управление инфраструктурой | сквозная автоматизация | обеспечение отказоустойчивости | автоматические реакции | сложные сценарии |