
- Паттерны для потоковых данных: как распознать и эффективно использовать
- Что такое потоковые данные?
- Ключевые понятия: что такое паттерн?
- Типы паттернов в потоковых данных
- Практическое применение паттернов
- Как распознавать паттерны в потоках?
- Практические инструменты для анализа потоков
- Практический пример: распознавание аномалий в логах сервера
- Вопрос-ответ
Паттерны для потоковых данных: как распознать и эффективно использовать
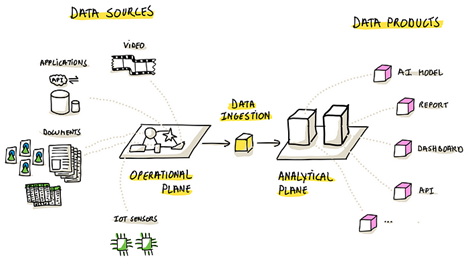
В современном мире‚ наполненном постоянным потоком информации‚ умение распознавать определённые паттерны (шаблоны) в потоковых данных становится ключевым навыком для аналитиков‚ разработчиков и бизнес-стратегов․ Потоковые данные – это непрерывные поступления информации‚ которые требуют мгновенного анализа и принятия решений․
На первый взгляд‚ процесс обработки потоковых данных кажется сложным и даже хаотичным․ Кажется‚ что каждое событие – это уникальный случай‚ и искать шаблоны в бесконечном потоке очень трудно․ Однако выделение определённых паттернов позволяет не только быстрее распознавать важные события‚ но и прогнозировать дальнейшее развитие ситуации‚ автоматизировать процессы и повышать качество бизнес-решений․
В этой статье мы расскажем‚ что такое паттерны для потоковых данных‚ как их распознавать‚ какие существуют основные типы и каким образом можно использовать их с максимальной выгодой․ Плюс‚ рассмотрим практические примеры и инструменты‚ которые помогут вам стать мастерами в анализе потоков․
Что такое потоковые данные?
Потоковые данные – это непрерывный поток информации‚ который поступает из различных источников в реальном времени․ К примеру‚ это могут быть:
- данные с сенсоров IoT-устройств;
- журналы серверов и лог-файлы;
- соцсети и платформы для обмена сообщениями;
- финансовые транзакции и биржевые данные;
- информация о пользователях на сайте или в приложении․
Обработка таких данных требует специальных подходов и инструментов‚ поскольку стандартные методы аналитики‚ ориентированные на статичные базы‚ зачастую оказываются недостаточными․ Важнейшее место в понимании потоков занимает именно распознавание шаблонов — тех особенностей‚ которые позволяют определить важные события или закономерности среди непрерывной массы информации․
Ключевые понятия: что такое паттерн?
Паттерн – это повторяющийся или характерный шаблон‚ закономерность‚ которая появляется в данных․ Чаще всего он помогает:
- Распознать важные события или аномалии․
- Выделить тренды и закономерности․
- Прогнозировать будущие значения или события․
Некоторые паттерны могут быть очень очевидными — например‚ регулярное увеличение трафика в определённое время суток․ Другие же требуют более глубокого анализа и специальных алгоритмов для выявления скрытых закономерностей․
Типы паттернов в потоковых данных
Различают множество паттернов в потоках․ Ниже перечислены основные группы и их особенности․
| Тип паттерна | Описание | Примеры |
|---|---|---|
| Повторяющиеся шаблоны | Паттерны‚ регулярно возникающие в данных‚ например‚ ежедневные пики активности․ | Количество посещений сайта по часам‚ расход топлива ночью и днем․ |
| Аномалии | Внезапные отклонения‚ которых раньше не было․ | Внезапный скачок ошибок в логах‚ неожиданный всплеск транзакций․ |
| Тренды | Долгосрочные направления изменения данных․ | Постепенное увеличение числа подписчиков․ |
| Циклы и сезонности | Повторяющиеся на определённых интервалах изменения․ | Продажи в праздничные дни‚ изменение температуры по сезонам․ |
| Обрывы и сегменты | Частичные или полные прекращения потока․ | Потеря соединения с сервером‚ отключение датчиков․ |
Практическое применение паттернов
Для организации эффективной работы с потоками важным этапом является обнаружение и использование этих паттернов․ Ниже рассмотрим‚ как именно этим заниматься․
Алгоритмы и методы:
- Модели машинного обучения: обучение на исторических данных для выявления повторяющихся и аномальных паттернов․
- Методы статистического анализа: скользящие средние‚ проверка на сезонность и тренды․
- Правила и эвристики: например‚ если количество ошибок превышает определённый порог‚ считать это аномалией․
Как распознавать паттерны в потоках?
Распознавание паттернов в потоковых данных — сложная‚ но интересная задача․ Важен правильный выбор инструментов и подходов․
Обзор основных методов:
- Обучение на исторических данных: предварительно подготовленные модели помогают быстрее обнаружить закономерности в новых потоках․
- Использование алгоритмов кластеризации: позволяют сгруппировать похожие события и выявить паттерны․
- Модель на основе правил: ручное описание правил и условий для обнаружения определённых ситуаций;
- Временные ряды и сезонный анализ: использование методов анализа временных рядов для выявления сезонных паттернов․
Практические инструменты для анализа потоков
На рынке существует множество решений‚ которые помогают в реализации анализа потоковых данных и выявления паттернов:
- Apache Kafka — платформа для потоковой обработки данных в реальном времени․
- Apache Flink — мощный движок для потоковых вычислений․
- Elasticsearch & Kibana — для визуализации данных и поиска паттернов․
- TensorFlow и scikit-learn — для построения предиктивных моделей и распознавания паттернов машинного обучения․
- Prometheus и Grafana — мониторинг и визуализация метрик потоков․
Практический пример: распознавание аномалий в логах сервера
Рассмотрим пример‚ который поможет понять‚ как использовать паттерны на практике; Представим‚ что мы следим за логами сервера в реальном времени․ Нам нужно обнаружить‚ когда происходят непредвиденные сбои или атаки․
Чтобы сделать это‚ мы можем применить следующий подход:
- Настроить сбор логов в потоковую систему (например‚ Kafka)․
- Применить алгоритмы машинного обучения или эвристики для анализа данных․
- Выделить паттерны‚ которые указывают на необычные ситуации‚ например‚ резкий рост ошибок или повторяющиеся запросы․
- Настроить оповещения и автоматическую реакцию․
Обнаружение паттернов в потокиров данных — это неотъемлемая часть современного анализа информации․ Умение распознавать‚ закреплять и использовать эти шаблоны позволяет значительно повысить эффективность бизнес-процессов‚ своевременно реагировать на изменения и предсказывать будущее․
Советуем:
- Постоянно тестировать и модернизировать ваши модели анализа․
- Использовать множество источников данных для повышения точности․
- Автоматизировать процессы обнаружения паттернов при помощи современных платформ․
Вопрос-ответ
Вопрос: Какие основные вызовы возникают при анализе потоковых данных‚ и как их преодолеть?
Ответ: Основными вызовами являются высокая скорость поступления данных‚ необходимость мгновенного реагирования‚ наличие шума и неполных данных‚ а также сложность в распознавании скрытых паттернов․ Для их преодоления рекомендуется использовать современные вычислительные платформы‚ алгоритмы машинного обучения и методы очистки данных․ Также очень важно правильно настраивать пороговые значения и проводить регулярную проверку моделей‚ чтобы они оставались актуальными и точными․
Подробнее
| Глубокий анализ потоковых данных | ||||
| Обнаружение аномалий в реальном времени | Методы анализа временных рядов | Инструменты потоковой обработки данных | Модели машинного обучения для потоков | Практики визуализации потоковых данных |
| Обработка больших данных в реальном времени | Обнаружение закономерностей | Автоматизация анализа потоков | Обучение на примерах потоковых данных | Интеграция» потоковых систем в бизнес-процессы |
>







